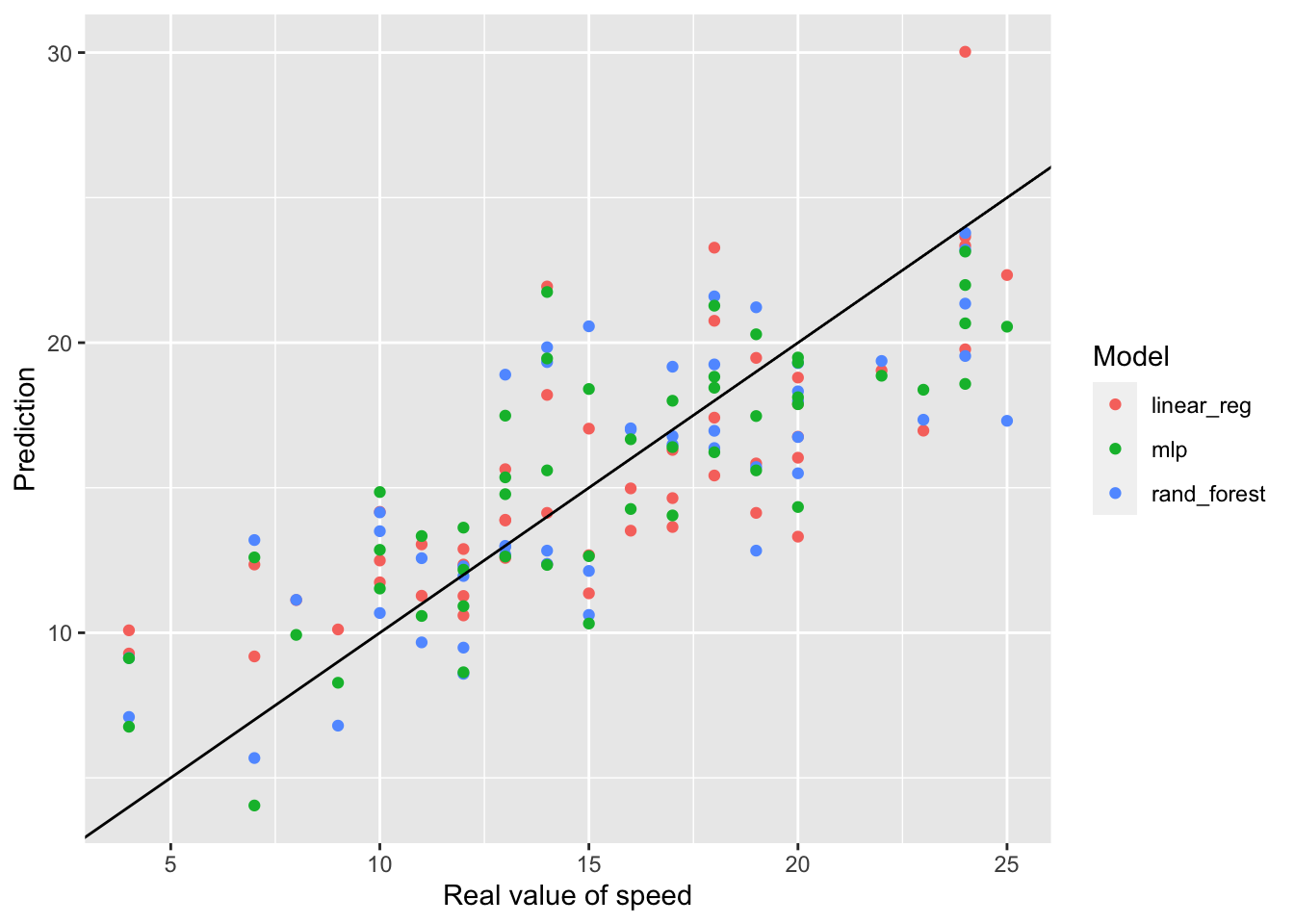
# Create data for resampling:
cars_folds <- vfold_cv(cars, v = 10, repeats = 1)
# Create model specifications:
lm_spec <- linear_reg()
rf_spec <- rand_forest() |> set_mode('regression')
nn_spec <- mlp(epochs = 500, hidden_units = 3, penalty = 0.01) |>
set_mode('regression')
# Create workflows:
all_workflows <-
workflow_set(
preproc = list("formula" = speed ~ dist),
models = list(lm = lm_spec,
rf = rf_spec,
nn = nn_spec)
)
# Run the workflows:
result <- all_workflows |>
workflow_map(resamples = cars_folds,
control = control_resamples(save_pred = TRUE))
# Display summary statistics for all model types:
(metrics <- collect_metrics(result))